これはドワンゴ Advent Calendar 2017の9日目の記事です。
漫画やアニメを見ていると、可愛い女の子になって可愛い女の子と他愛もない会話をして過ごす日常に憧れます。 そんな感じで、可愛い女の子になりたい人は多いと思います1。 しかし残念なことに、現在の技術で真の可愛い女の子になるのはとても難しいです。 じゃあせめて仮想でいいから可愛い女の子になりたいですよね(バーチャルyoutuberキズナアイみたいな)。 しかし、仮に姿を可愛い女の子にしても、声が可愛くなければ願いは叶いません。 ということで、声を可愛くする声質変換を目指してみました。 今回は僕の声をDeepLearningの力を借りて結月ゆかりにしました。
お勉強
まずは音声の勉強をします。 これが一番時間かかりました。 最近の音声合成手法は3種類あります。
- 音響特徴量+vocoder
- wavenet
- STFT+位相推定
今回使ったのは音響特徴量+vocoderですが、紹介がてらこれらを簡単に説明していきます。
音響特徴量+vocoder
声と音響特徴量(基本周波数、スペクトラム、非周期信号)を相互変換して音声合成する手法です。 基本周波数は声の高さ、スペクトラムは声質、非周期信号は子音とかの情報をうまくコードすることが期待されています。 声と音響特徴量を相互変換する仕組みがvocoderです。 話者Aの音声から、話者Bの対応する基本周波数・スペクトラムを推定することで声質変換ができます。 非周期信号は推定無しで、そのまま転写すればいいとのこと。 数年前まで、音響特徴量の推定にはGMMが用いられてきましたが、近年はDeepで換装した報告が多くあります。
wavenet
自己回帰モデルを使って生の音声を直接推定する手法です。 とても綺麗な音声を合成できることが知られていますが、学習に時間がかかります。 自己回帰モデルをなので当然生成に時間がかかります。 が、後者の問題に関しては、先月高速に音声合成できるらしい手法が提案されました。 お金とデータがいっぱいあるならこの手法が一番良さそうです。
STFT+位相推定
生の音声よりは推定しやすそうなSTFTを経由して音声合成する手法です。 STFTを推定した後、さらに位相推定して音声を復元します。 位相推定には古き良き手法がよく用いられますが、この手法は推定に時間がかかるので、リアルタイム音声合成には向きません。 STFTは画像なので、画像生成分野の手法をそのままこれに適用するのが流行るかと思ってましたが、全然流行りませんでした。
データセットの準備
voiceloid2の結月ゆかりの音声と、自分の音声を用いました。 まず結月ゆかりに503文読んでもらい、それを僕が読みます。 僕は下手くそだったのと、録り直ししたのとで十数時間かかりました。 もう二度とやりたくありません。 波形をスペクトログラムにしたのがこちらで、見て分かる通り音声がズレています。


統計的声質変換の学習には、このズレが無い綺麗なデータが必要です。 そのため音声アライメントする必要があります。 今回は無音区間を省いてMFCCを求め、DTWを使ってアライメントしました(詳細:声優統計コーパスをアライメントしてみる)。 あとついでに、特徴量がN(0,1)になるように正規化しました。
モデル
時系列データを生成でき、かつ変換手法に適していそうなresidual構造のあるものを使います。 ちょうどよかったので音声合成で良い性能を叩き出したTacotronモデルの一部を使いました。
学習条件
損失関数は目標の音声と合成した音声の平均絶対誤差にしました。
音響特徴量は無声区間とそうじゃない区間で意味が変わってきます。 例えば無声区間では基本周波数に意味がありません。 僕はこの部分の損失が0になるようにマスクして学習させました。
他にもここに書いてないような細かい処理を色々しています。 他の条件はまあソースコードを参照ということで。。
結果
学習させてみました。全然ダメでした。
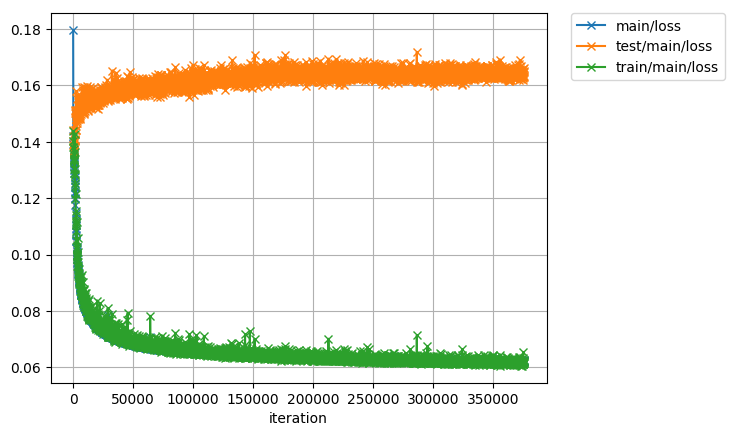
めっちゃ過学習します。モデルを弱くしてもやっぱり過学習します。 時間がなかったので、入出力に大量にノイズ乗せて学習することにしました。 学習したモデルを使って学習データを変換した結果はこうなりました。
変換された音声はまあ、四捨五入すると結月ゆかりでした。 ちなみに入力音声と目標音声はこんな感じです。
学習済みモデルを使っていろいろ試してみました。
テスト音声
先ほどの例は学習に用いた音声を変換しました。 学習に用いていないテスト音声を変換してみます。
学習に用いた音声と同程度のクオリティでした。 長い音声だと最後の方の声がふにゃふにゃになる傾向がありました。
歌ってみた
歌は母音の期間が長いので声質変換の結果がよく聞こえるらしいです。 ということで歌ってみました。
音程がだいぶ揺れていました。歌は苦手なようです。
ささやき声
可愛い女の子に耳元でささやかれたい人は多いと思います。 ささやき声は母音が消えやすく、結構特殊な音声らしいです。 ということで、ささやき声も変換してみました。
だいぶぶっ壊れていました。結構難しいようです。
他の人の音声
これは「僕の声を」結月ゆかりにするプロジェクトです。 この世に結月ゆかりは3人も必要ありません。 他の人の声も変換できちゃうとダメです。 僕の声だけを使って学習させたモデルを使って、他の人の音声も変換してみました。
他の人の音声でもなんとなく変換できていましたが、僕の声が一番綺麗に変換できていました。
その他試行錯誤
DRAGAN
DRAGANは、画像生成分野でわりといい結果を出してる手法です。 この手法を適用した判別器に、pix2pixのように条件付けした音声を入力して学習してみました。 まだパラメータ調整がうまく行っていないのかきれいな結果は得られていません。 代わりに、実験者の正気度を下げるような結果が生成されました。
これはこれで何かに使えそうですね。
感想
この程度のクオリティじゃ全然満足できないので、ちょくちょく改良していきたいと思います。 あと、音声について色々学べたので、今後も色々やっていきたいです。 成功したら、VRで結月ゆかり1になって、フル仮想してみたいです。