畳み込みニューラルネットを使ったピッチ推定手法、CREPEが提案された1。 PyPIが用意されていて、発話音声にも簡単に適用できそうだったので試してみた。
使用方法はとても簡単で、以下のコマンドを叩けば良い。
pip install crepeGPUを使ったほうが圧倒的に早い。 CREPEはKeras製なので、tensorflow-gpuを導入すればGPU使用可能になる。
pip install tensorflow-gpuGitHubでの説明によると、コマンドとして使うことが想定されている。 コードはちゃんと機能ごとに切り分けられているので、適切にimportすればPython内で使うこともできる。
import librosa
from crepe.core import build_and_load_model as crepe_build
from crepe.core import predict as crepe_predict
fs = 16000
x, _ = librosa.load('hoge.wav', sr=fs)
crepe_build()
t, f0, confidence, _ = crepe_predict(x, sr=fs, viterbi=True)
threshold = 0.1
f0[confidence < threshold] = 0CREPEは、ピッチの確率分布のようなものを推定したあと、その分布を元にピッチを定める。
viterbi=False(初期値)の場合は確率が最大のピッチを、viterbi=Trueの場合はHMMを使ってよしなにピッチを推定するっぽい(論文読んでいない)。confidenceの値は音声活動の信頼度(0~1)らしい。
WORLDのHarvestを用いて基本周波数を推定したものと、CREPEを比較してみた。
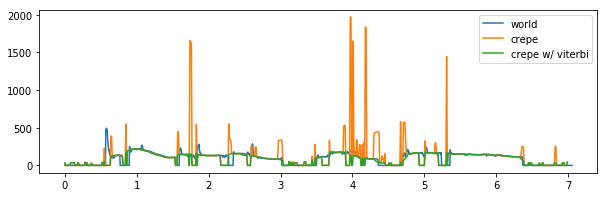
viterbi=Falseだと値が吹っ飛ぶことが多いようだった。
続いて、推定したf0を元に、WORLDを用いて分析合成してみた。
WORLDが一番良いように聞こえる。 CREPEはフレーム時間が0.01秒固定で、WORLDは0.005秒なので、その差が出ているのかもしれない。
上の音声(約7秒)の推定時間は、Harvestが2.0秒、viterbiなしCREPEが1.0秒、viterbiありが1.3秒程度だった。 GPU無しCREPEだと10秒程度かかった。
CREPEはWORLDほどバッファが必要ない(たぶん)ので、リアルタイム性が必要なサービスに使いやすそうだ。 しかし、HMMを利用する場合は、前の音声のコンテキストが必要なはずだが、そこは実装されていないので、自分でどうにかしないといけない。
作図に用いたJupyter notebookファイルをGistにアップロードした。