この記事は、ドワンゴ Advent Calendar 2019の1日目の記事です。
モチベーション
最近、理想の人工知能(歌ったり踊ったり喋ったりできるキャラクター)を作りたいと思うようになりました。人工知能が歌を歌うためには、歌声音声合成エンジンが必要です。ということで、ディープラーニングを使って、歌声音声合成エンジンの作成に挑戦してみました。この記事では、実際に音声合成した歌声や、その仕組み、別条件での実験結果、ディープラーニング周りの手法を紹介します。
デモ動画
実際に作成した音声合成エンジンを使った歌唱のデモです。
(歌声音声合成を作ったら絶対最初にカバーしたいと思っていた歌、ハジメテノオトのカバーです。)
まだ挑戦し始めてから2週間ほどしか経っていないのでかなり荒削りですが、それでもちゃんと歌詞や音程が取れていたり、溜めの部分で大きく息を吸う音が入っていたりと、そこそこの成果をあげることができました。
仕組みの紹介
歌唱データを用いてディープラーニングして歌声音声合成エンジンを作り、そのエンジンを使って歌を生成しています。生成する歌は、ディープラーニングに用いた歌唱データに含まれないような新しい歌でも大丈夫です。
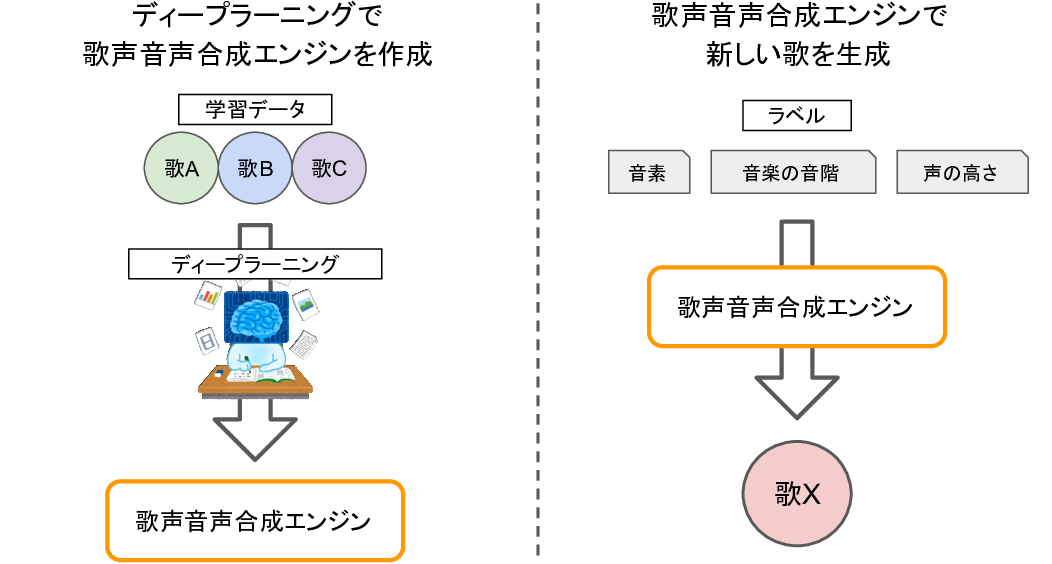
ディープラーニングには、DeepMindやGoogle Brainの方が提唱したWaveRNNというネットワーク構造を用いています。サンプリングレートは24000Hz、ビット深度は10bitです(詳細は後述)。
今回作った音声合成エンジンでは、次の3つの時系列ラベルを入力すると、歌の音声波形が生成できるようにしました。
- 音素(母音や子音)
- 音楽の音階(ドレミファソラシド)
- 声の高さ(周波数)
つまり、歌詞と楽譜と声の高さとタイミングを指定すれば、歌が生成される感じです。
ディープラーニングには東北きりたん歌唱データベースの音声データを活用しました。こちらのデータベースには、東北きりたんというキャラクターがアカペラで歌った歌唱データや音素ラベルが50曲も収録されています。

別条件での実験結果
せっかく歌声音声合成エンジンができたので、いろいろな条件で結果がどうなるか実験してみました。
声の高さラベルを省いてディープラーニングしたとき
歌を歌うとき、基本的には音楽の音階に沿って声の高さを変えて歌います。このとき、声の高さにわざと高低をつけて、歌に表現力を持たせることができます(ビブラートなど)。先ほどのデモでは声の高さラベルも入力していますが、これを省いてディープラーニングすれば、声の高さも良い感じに生成してくれて、元の歌声に近い表現になるかもしれません。ということで、声の高さラベルを省いてディープラーニングを行い、その音声合成結果を聞いてみました。
結果を聞くと、へにょへにょした歌声になってしまうことがわかりました。こうなった原因はおそらく、今回用いたディープラーニング手法は、時間方向に一貫している音声波形の生成が苦手だったからだと考えています。例えばビブラートは、一定のリズムかつ一定の高低差で声の高さを揺らして表現しますが、今回の手法はこの「一定にする」ことが難しかったんだと思います。
声の大きさラベルを足してディープラーニングしたとき
先ほどのデモを聞いてみると、声の大きさが安定していない印象を受けます。これはおそらく、前述と同様に今回の手法は「一定にする」ことが難しく、声の大きさをうまく調整できないためだと思われます。ということは、声の大きさラベルを足せば、もっと安定した歌声になるはずです。声の大きさラベルを足してディープラーニングし、その結果を聞いてみました。
結果を聞くと、ノイズのような歌声になってしまうことがわかりました。これは・・・なんでこうなるのか、全く見当がつきません。ディープラーニングはこんな感じで、問題が発生したとき、その問題が真に解決不可能なのか、それともただプログラムがバグっているだけなのかを切り分けづらく、もやもやすることがあります。今回のこの問題は、原因不明です。
(2019/12/08追記)声の大きさラベルの値を全体的に小さくしてみたところ、品質がかなり上がりました。ディープラーニングなにもわからない。
ディープラーニング周りの紹介
音声合成エンジンの作成にはディープラーニング、つまり機械学習を用いています。ここでは、今回用いた用いディープラーニング手法や、学習データの前処理を紹介します。ここはちょっと技術寄りの説明になります。
end-to-end音声合成
機械学習を用いて音声合成する手法は、音声波形を直接生成するのではなく、音響特徴量を生成したあと、ボコーダーと呼ばれる変換器を使って音声波形にする手法が主流でした。この方法は、声に関連する特徴量だけを生成すれば良いため、少ないデータ数で機械学習することができます。しかし、一度特徴量にすると、呼吸音などの情報が欠け落ちてしまいます1。呼吸音は尊いので、なんとしてでも救いたいです。そのために、ラベルから音声波形を直接生成する手法(end-to-end音声合成)に挑戦してみました。
音声波形は特徴量に比べて情報量が大きいため、学習するのがより難しくなります。東北きりたん歌唱データベースには約1時間という十分な量の歌唱データがあるため、なんとかなるだろうと思ってこちらの手法にしました。今回は、前々から追実装して手軽に使える環境があったので、WaveRNN(の改造版)を用いました。
学習に関する詳細
学習に用いる音声データは、サンプリングレートを24000Hz、ビット深度を10bitにしました。音素ラベルや音階ラベルは自作のリーダーを用いて読み込み、音階ラベルが欠けている箇所を省きました。音素ラベル・音階ラベルはそれぞれone-hotベクトルにし、それぞれのラベルの持続時間を加えたものを入力としました。歌声の周波数はWORLDを用いて推定し、その対数を入力としました。ネットワークは、WaveRNNのdual-softmaxを失くし、ラベルデータを双方向GRUを2層通過させたデータを局所ベクトルとして用いました。バッチサイズを32にし、0.07秒の音声波形を1データとしました。このとき、ラベルデータを前後1秒ずつほど長くサンプルして双方向GRUに通し、音声波形に合わせてトリミングして学習すると、性能が大きく改善しました。20万イテレーション学習したモデルを用いて音声合成しました。学習完了までに、TITAN Xで3日ほどかかりました。
終わりに
今回は実験報告をゴールにしていたので適当にタスクを設計しました。作った歌声音声合成エンジンを誰でも使えるようにしようと考えてみたところ、何を入力にし、何を推定し、何を修正可能にするのか過不足なく設定するのって難しそうだなぁと思いました。例えば先ほど、音量を調整可能にするために音量ラベルを入力する実験を紹介しましたが、音量程度であれば推定後のポストプロセスで正規化しちゃうことも可能だな~と、さっき気づきました。発見が多くて楽しいです。
- 1.2020/04/28追記:ボコーダーは呼吸音も合成できるとご指摘いただきました、ありがとうございます。 ↩